df_2015 <- read.csv("data/2015.csv")
df_2016 <- read.csv("data/2016.csv")
df_2017 <- read.csv("data/2017.csv")
df_2018 <- read.csv("data/2018.csv")
df_2019 <- read.csv("data/2019.csv")
df_2020 <- read.csv("data/2020.csv")
df_2021 <- read.csv("data/2021.csv")
df_2022 <- read.csv("data/2022.csv")
df_2023 <- read.csv("data/2023.csv")
str(df_2015)
str(df_2016)
str(df_2017)
str(df_2018)
str(df_2019)
str(df_2020)
str(df_2021)
str(df_2022)
str(df_2023)
library(dplyr)
#2015
# Read CSV files and import into dataframes
file_1 <- read.csv("data/2015.csv")
happiness_2015_df <- file_1
# Clean up the dataframe to rename data and match to all other years
happiness_2015_df <- happiness_2015_df %>%
select(-Region) %>%
rename(`Happiness Rank` = `Happiness.Rank`,
`Happiness Score` = `Happiness.Score`,
`Economy` = `Economy..GDP.per.Capita.`,
`Health` = `Health..Life.Expectancy.`,
`Government Corruption` = `Trust..Government.Corruption.`,
`Dystopia Residual` = `Dystopia.Residual`) %>%
select(-`Standard.Error`)
# Display the first few rows
head(happiness_2015_df)
#2016
file_2 <- read.csv("data/2016.csv")
happiness_2016_df <- file_2
# Clean up the dataframe to rename data and match to all other years
happiness_2016_df <- happiness_2016_df %>%
select(-Region) %>%
rename(`Happiness Rank` = `Happiness.Rank`,
`Happiness Score` = `Happiness.Score`,
`Economy` = `Economy..GDP.per.Capita.`,
`Health` = `Health..Life.Expectancy.`,
`Government Corruption` = `Trust..Government.Corruption.`,
`Dystopia Residual` = `Dystopia.Residual`) %>%
select(-`Lower.Confidence.Interval`, -`Upper.Confidence.Interval`)
# Display the first few rows
head(happiness_2016_df)
#2017
file_3 <- read.csv("data/2017.csv")
happiness_2017_df <- file_3
# Clean up the dataframe to rename data and match to all other years
happiness_2017_df <- happiness_2017_df %>%
rename(
`Happiness Rank` = `Happiness.Rank`,
`Happiness Score` = `Happiness.Score`,
`Economy` = `Economy..GDP.per.Capita.`,
`Health` = `Health..Life.Expectancy.`,
`Government Corruption` = `Trust..Government.Corruption.`,
`Dystopia Residual` = `Dystopia.Residual`
) %>%
select(-`Whisker.high`, -`Whisker.low`)
# Display the first few rows
head(happiness_2017_df)
#2018
file_4 <- read.csv("data/2018.csv")
happiness_2018_df <- file_4
# Clean up the dataframe to rename data and match to all other years
happiness_2018_df <- happiness_2018_df %>%
rename(
`Happiness Rank` = `Overall.rank`,
`Country` = `Country.or.region`,
`Happiness Score` = `Score`,
`Economy` = `GDP.per.capita`,
`Family` = `Social.support`,
`Health` = `Healthy.life.expectancy`,
`Freedom` = `Freedom.to.make.life.choices`,
`Government Corruption` = `Perceptions.of.corruption`
)
# Assuming we want to convert the 'Happiness.score' column to numeric
happiness_2018_df$`Government Corruption` <- as.numeric(gsub(",", ".", happiness_2018_df$`Government Corruption`))
# Display the first few rows
head(happiness_2018_df)
#2019
file_5 <- read.csv("data/2019.csv")
happiness_2019_df <- file_5
# Clean up the dataframe to rename data and match to all other years
happiness_2019_df <- happiness_2019_df %>%
rename(
`Happiness Rank` = `Overall.rank`,
`Country` = `Country.or.region`,
`Happiness Score` = `Score`,
`Economy` = `GDP.per.capita`,
`Family` = `Social.support`,
`Health` = `Healthy.life.expectancy`,
`Freedom` = `Freedom.to.make.life.choices`,
`Government Corruption` = `Perceptions.of.corruption`
)
# Display the first few rows
head(happiness_2019_df)
# Add the 'Dystopia Residual' column to the 2018 and 2019 dataframes
happiness_2018_df$`Dystopia Residual` <- NA
happiness_2019_df$`Dystopia Residual` <- NA
#2020
file_6 <- read.csv("data/2020.csv")
happiness_2020_df <- file_6
# Clean up the dataframe to rename data and match to all other years
happiness_2020_df <- happiness_2020_df %>%
select(-`Generosity`) %>%
rename(
`Country` = `Country.name`,
`Happiness Score` = `Ladder.score`,
`Economy` = `Explained.by..Log.GDP.per.capita`,
`Family` = `Explained.by..Social.support`,
`Health` = `Explained.by..Healthy.life.expectancy`,
`Freedom` = `Explained.by..Freedom.to.make.life.choices`,
`Government Corruption` = `Explained.by..Perceptions.of.corruption`,
`Generosity` = `Explained.by..Generosity`,
`Dystopia Residual` = `Dystopia...residual`
) %>%
select(-`Regional.indicator`, -`Standard.error.of.ladder.score`, -`upperwhisker`, -`lowerwhisker`,-`Logged.GDP.per.capita`, -`Social.support`, -`Healthy.life.expectancy`, -`Freedom.to.make.life.choices`, -`Perceptions.of.corruption`, -`Ladder.score.in.Dystopia`)
# Add a "Happiness Rank" column after the "Country" column
happiness_2020_df <- happiness_2020_df %>%
mutate(`Happiness Rank` = rank(-`Happiness Score`, ties.method = "first")) %>%
select(Country, `Happiness Rank`, everything())
#Display the first few rows
head(happiness_2020_df)
#2021
file_7 <- read.csv("data/2021.csv")
happiness_2021_df <- file_7
# Clean up the dataframe to rename data and match to all other years
happiness_2021_df <- happiness_2021_df %>%
select(-`Generosity`) %>%
rename(
`Country` = `Country.name`,
`Happiness Score` = `Ladder.score`,
`Economy` = `Explained.by..Log.GDP.per.capita`,
`Family` = `Explained.by..Social.support`,
`Health` = `Explained.by..Healthy.life.expectancy`,
`Freedom` = `Explained.by..Freedom.to.make.life.choices`,
`Government Corruption` = `Explained.by..Perceptions.of.corruption`,
`Generosity` = `Explained.by..Generosity`,
`Dystopia Residual` = `Dystopia...residual`
) %>%
select(-`Regional.indicator`, -`Standard.error.of.ladder.score`, -`upperwhisker`, -`lowerwhisker`,-`Logged.GDP.per.capita`, -`Social.support`, -`Healthy.life.expectancy`, -`Freedom.to.make.life.choices`, -`Perceptions.of.corruption`, -`Ladder.score.in.Dystopia`)
# Add a "Happiness Rank" column after the "Country" column
happiness_2021_df <- happiness_2021_df %>%
mutate(`Happiness Rank` = rank(-`Happiness Score`, ties.method = "first")) %>%
select(Country, `Happiness Rank`, everything())
#Display the first few rows
head(happiness_2021_df)
#2022
file_8 <- read.csv("data/2022.csv")
happiness_2022_df <- file_8
# Convert only specific columns that contain numbers
numeric_cols <- c('Happiness.score', 'Explained.by..GDP.per.capita', 'Explained.by..Social.support',
'Explained.by..Healthy.life.expectancy', 'Explained.by..Freedom.to.make.life.choices',
'Explained.by..Perceptions.of.corruption', 'Explained.by..Generosity',
'Dystopia..1.83....residual')
happiness_2022_df[numeric_cols] <- lapply(happiness_2022_df[numeric_cols], function(x) {
as.numeric(gsub(",", ".", x))
})
# Clean up the dataframe to rename data and match to all other years
happiness_2022_df <- happiness_2022_df %>%
rename(
`Happiness Rank` = `RANK`,
`Happiness Score` = `Happiness.score`,
`Economy` = `Explained.by..GDP.per.capita`,
`Family` = `Explained.by..Social.support`,
`Health` = `Explained.by..Healthy.life.expectancy`,
`Freedom` = `Explained.by..Freedom.to.make.life.choices`,
`Government Corruption` = `Explained.by..Perceptions.of.corruption`,
`Generosity` = `Explained.by..Generosity`,
`Dystopia Residual` = `Dystopia..1.83....residual`
) %>%
select( -`Whisker.high`, -`Whisker.low`)
#Display the first few rows
head(happiness_2022_df)
#2023
file_9 <- read.csv("data/2023.csv")
happiness_2023_df <- file_9
# Clean up the dataframe to rename data and match to all other years
happiness_2023_df <- happiness_2023_df %>%
select(-`Generosity`) %>%
rename(
`Country` = `Country.name`,
`Happiness Score` = `Ladder.score`,
`Economy` = `Explained.by..Log.GDP.per.capita`,
`Family` = `Explained.by..Social.support`,
`Health` = `Explained.by..Healthy.life.expectancy`,
`Freedom` = `Explained.by..Freedom.to.make.life.choices`,
`Government Corruption` = `Explained.by..Perceptions.of.corruption`,
`Generosity` = `Explained.by..Generosity`,
`Dystopia Residual` = `Dystopia...residual`
) %>%
select( -`Standard.error.of.ladder.score`, -`upperwhisker`, -`lowerwhisker`,-`Logged.GDP.per.capita`, -`Social.support`, -`Healthy.life.expectancy`, -`Freedom.to.make.life.choices`, -`Perceptions.of.corruption`, -`Ladder.score.in.Dystopia`)
# Add a "Happiness Rank" column after the "Country" column
happiness_2023_df <- happiness_2023_df %>%
mutate(`Happiness Rank` = rank(-`Happiness Score`, ties.method = "first")) %>%
select(Country, `Happiness Rank`, everything())
#Display the first few rows
head(happiness_2023_df)
# Adding 'Year' column to each dataframe
happiness_2015_df$Year <- 2015
happiness_2016_df$Year <- 2016
happiness_2017_df$Year <- 2017
happiness_2018_df$Year <- 2018
happiness_2019_df$Year <- 2019
happiness_2020_df$Year <- 2020
happiness_2021_df$Year <- 2021
happiness_2022_df$Year <- 2022
happiness_2023_df$Year <- 2023
# Save the updated combined dataset
write.csv(happiness_2015_df, 'data/cleaned_2015_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2016_df, 'data/cleaned_2016_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2017_df, 'data/cleaned_2017_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2018_df, 'data/cleaned_2018_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2019_df, 'data/cleaned_2019_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2020_df, 'data/cleaned_2020_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2021_df, 'data/cleaned_2021_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2022_df, 'data/cleaned_2022_df.csv', row.names = FALSE)
# Save the updated combined dataset
write.csv(happiness_2023_df, 'data/cleaned_2023_df.csv', row.names = FALSE)
# Creating a list of all dataframes for easier handling
list_of_dfs <- list(happiness_2015_df, happiness_2016_df, happiness_2017_df, happiness_2018_df,
happiness_2019_df, happiness_2020_df, happiness_2021_df, happiness_2022_df,
happiness_2023_df)
# Merging all dataframes into one
happiness_all_years_df <- dplyr::bind_rows(list_of_dfs)
# Check the combined dataframe
print(happiness_all_years_df)
str(happiness_all_years_df)World Happiness Report
A Journey through World Happiness:)
Abstract
This project focuses on developing an interactive Shiny application to transform the intricate data from the World Happiness Report into an accessible and engaging platform for a diverse audience. While the report offers valuable insights into the happiness and well-being of individuals across countries, the complexity of the data often poses challenges in interpretation. Our objective is to simplify this process by creating an intuitive and user-friendly app that dynamically visualizes the data. The driving force behind our initiative is to bridge the gap between the richness of complex data and end-users seeking comprehension.
Data Cleaning code:
Introduction
In a world that constantly grapples with various challenges, understanding what contributes to human happiness has never been more crucial. The World Happiness Application is designed to unravel the complexities of what makes societies thrive in terms of happiness and well-being. Drawing upon data from the esteemed World Happiness Report, this interactive Shiny application offers a multifaceted view of global happiness dynamics.
The application is built on a foundation of robust and clean data, sourced from the comprehensive annual reports that explore the state of global happiness. These reports rank countries based on several happiness indicators including economic factors like GDP per capita, social factors like family and community support, health life expectancy, personal freedom, perceived government and business corruption, and generosity. By amalgamating data from the years 2015 to 2023, our application provides a unique longitudinal perspective on how happiness indices have evolved globally.
One of the core features of the World Happiness Application is its interactivity and user-friendly interface, developed using R Shiny, a powerful web application framework. Users can engage with a variety of data visualizations, including scatter plots, time series graphs, and heatmaps, to delve deeper into the happiness trends of different countries and regions. Each visualization is designed to be both informative and intuitive, offering users the flexibility to select specific years, countries, and happiness variables for comparison.
A key aspect of the application is the “Happiness Trends” plot, which visualizes how the happiness ranks of various countries have shifted over the years, providing insights into the trajectories of nations in their pursuit of well-being. Another highlight is the “World Heatmap,” a choropleth map that vividly depicts happiness rankings across the globe, inviting users to explore geographical patterns in happiness.
Question 1: Aspects influencing well-being over time.
Introduction
How do various factors impact the overall happiness score across different countries over the years?
We explore the complex interactions between many elements that affect general well-being in our quest to comprehend happiness on a global scale. We seek to understand how factors, such as economic stability, family support, health, freedom, trust in society, and generosity, affect the overall happiness scores throughout time and in different nations. By enabling users to interact with the data, this exploration reveals the complex connections between these important variables and the pursuit of happiness as a group.
In our pursuit to understand happiness on a global scale, we delve into the intricate interplay of diverse factors that contribute to overall well-being. By examining economic stability, family support, health, freedom, trust in society, and generosity, we aim to discern how these facets influence the overarching happiness scores across different countries and over time. This exploration empowers users to interactively engage with data, unraveling the intricate relationship between these pivotal factors and the collective pursuit of happiness.
Approach
In our interactive Shiny application, we offer users an intuitive platform for dynamic data exploration. Featuring three dropdown menus for the x-axis, y-axis, and country selection (allowing multi-country selection), alongside nine buttons for years spanning from 2015 to 2023, users can precisely pinpoint specific years for analysis. Additionally, a slider facilitates the selection of the number of countries to display.
The heart of the app resides in the ‘Plot’ tab, where users can select any two factors, including the happiness score, for the x and y axes. Each selection generates a data point on the graph, and upon hovering over these points, Plotly provides detailed insights related to the chosen factors and countries. This setup grants users the power to delve into individual factor analyses and country comparisons, fostering a deeper understanding of the data dynamics.
Analysis
The Happiness Report examining six factors in the year 2019 as an example.
library(markdown)
library(DT)
library(ggplot2)
library(dplyr)
library(plotly)
library(here)
library(sf)
library(rnaturalearth)
library(rnaturalearthdata)
library(grid)
library(patchwork)ggplot(data = happiness2015) +
geom_point(aes(x = Economy, y = Happiness.Score,
colour = Region, label = Country), size = 3) +
geom_smooth(aes(x = Economy, y = Happiness.Score),
method = "lm", color = "black", se = FALSE) +
ggtitle("Economy vs Happiness Score") +
theme_bw() +
theme(legend.position = "bottom")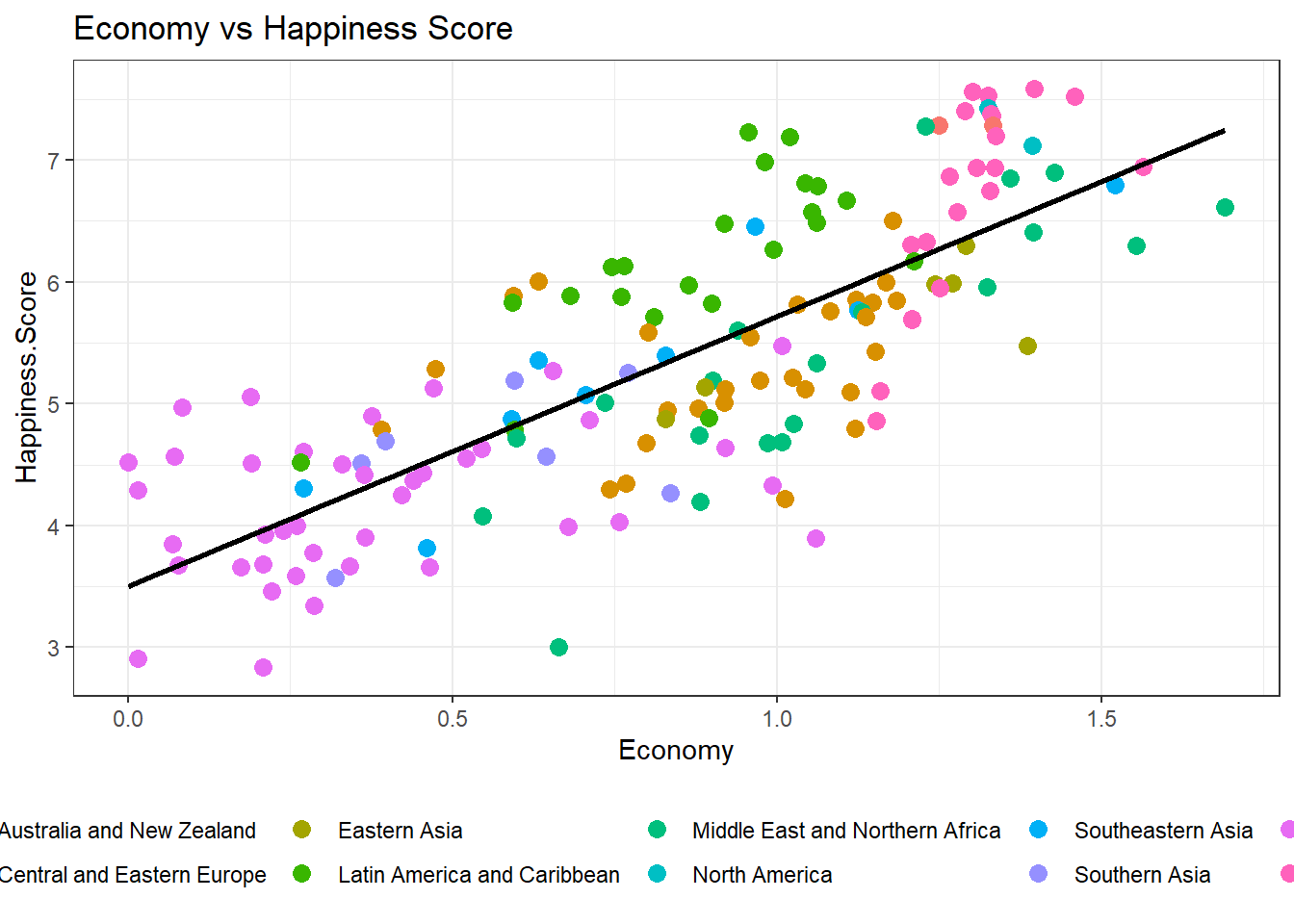
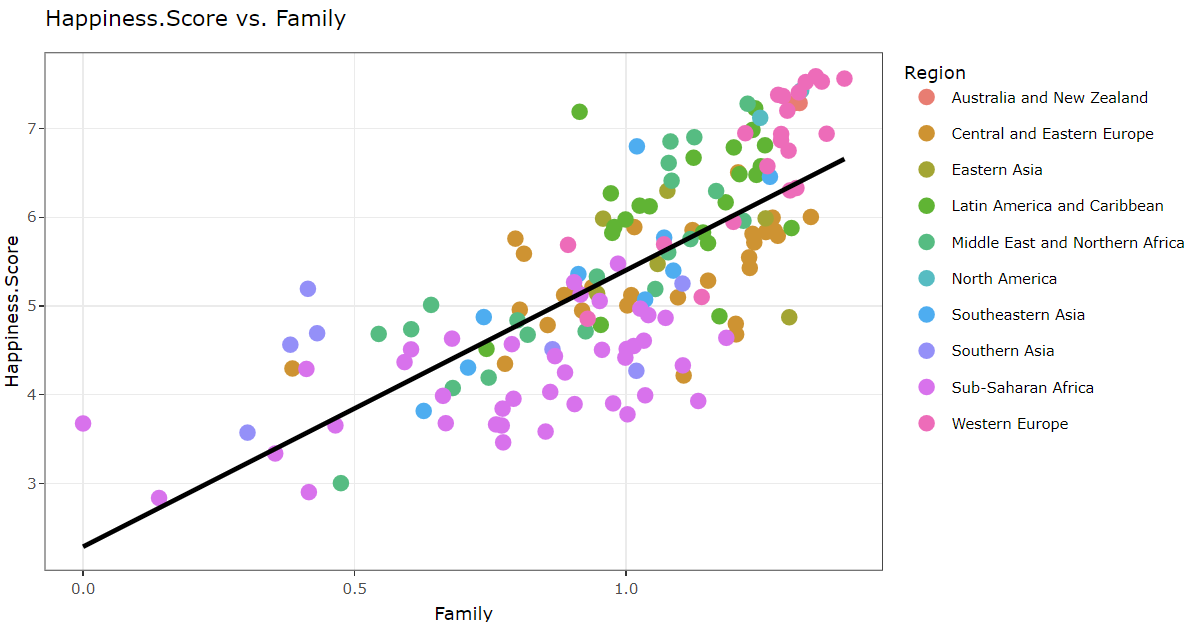
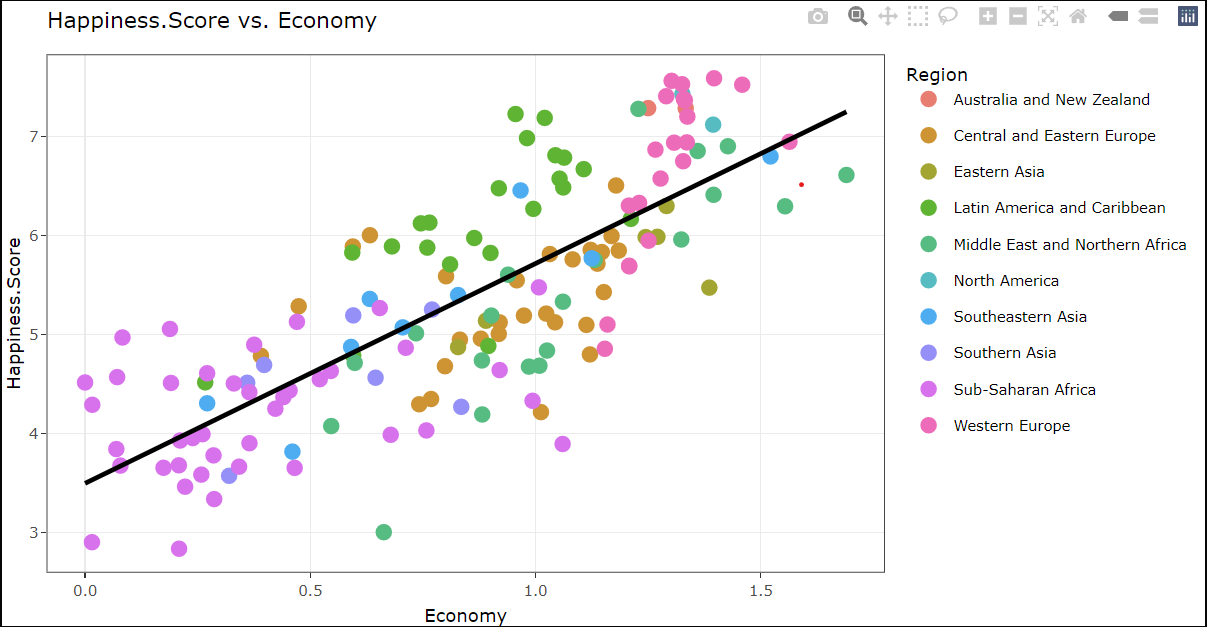
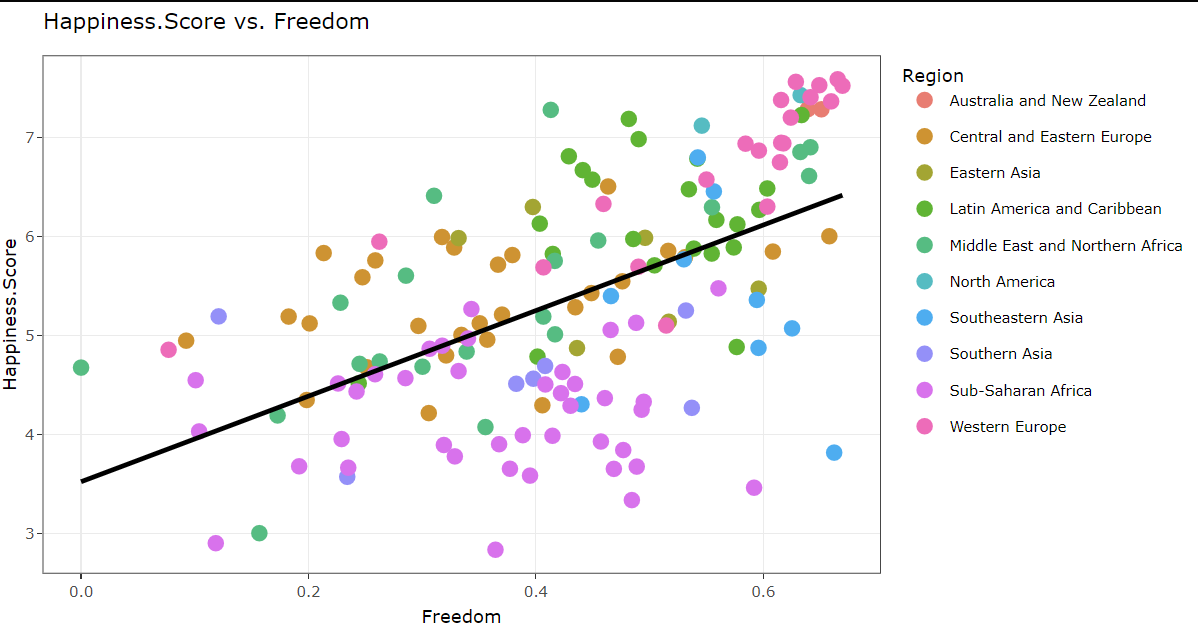
Discussion
Across the temporal spectrum from 2015 to 2023, our observation between Family (social support) and Happiness Score revealed intriguing insights. Initially, higher degrees of family support aligned with notably higher happiness scores. Subsequently, while the scores remained elevated, both the number of instances and the degree of family support slightly decreased. However, a resurgence followed, mirroring the initial phase’s trend before experiencing a slight decline towards the end. Overall, this analysis underscores a proportional relationship, emphasizing that increased family support correlates positively with higher happiness scores—a compelling testament to its pivotal role as a contributing factor in fostering well-being.
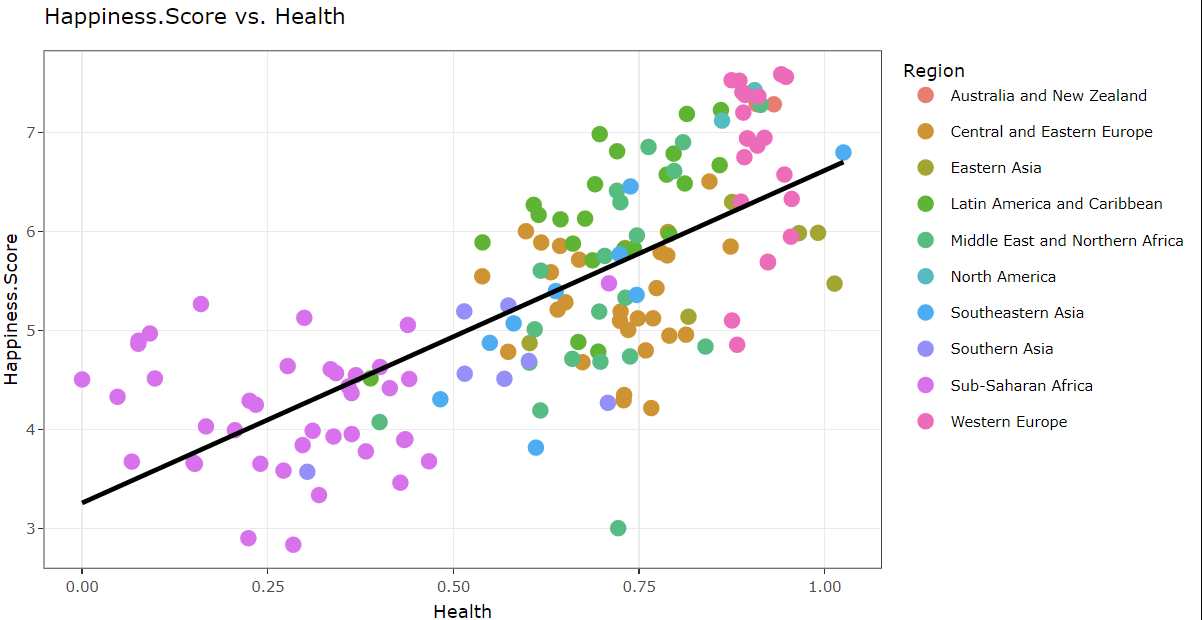
The correlation between health and happiness scores appears relatively consistent from 2015 to 2023, showing limited variations. Western European countries consistently maintain top positions, while Sub-Saharan African nations consistently rank at the bottom in this regard. Over the years, a clear pattern emerged: as the economy (GDP per capita) grew, so did happiness scores. Though the intensity varied, the trend remained consistent. In 2022, this link intensified, indicating a proportional relationship between a thriving economy and higher happiness.
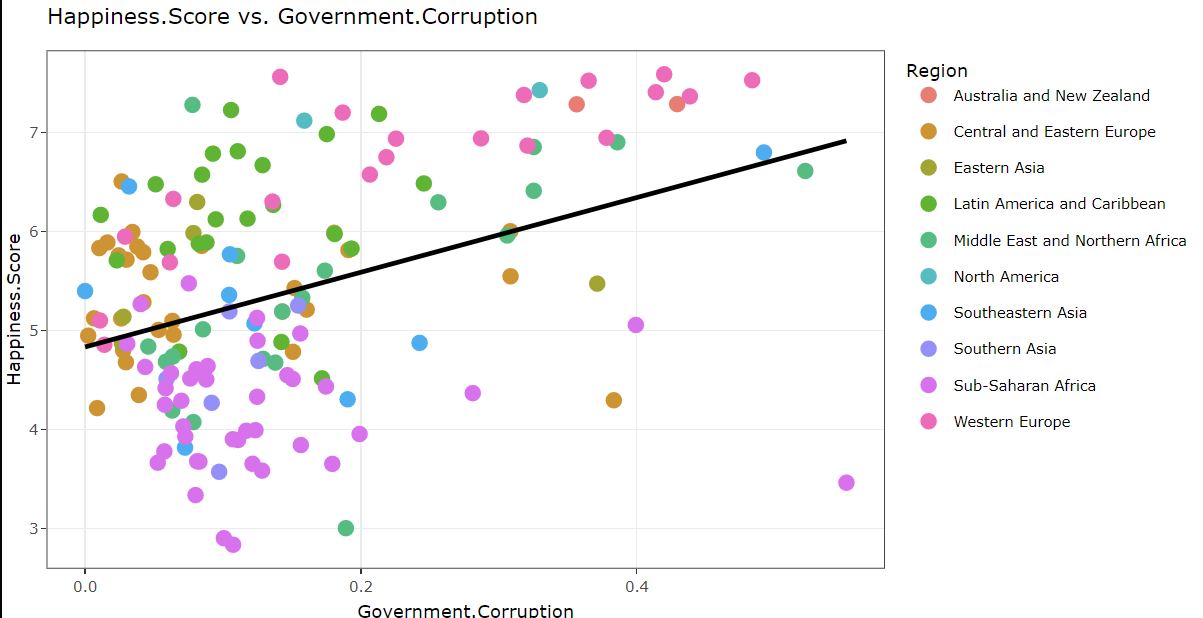
When comparing Trust (government corruption) and Happiness Score across countries, intriguing trends emerged. Western European nations like Finland, Denmark, Switzerland, and Sweden showed higher corruption levels but sustained higher happiness. Conversely, countries like New Zealand, Singapore, and Qatar followed a similar pattern. Rwanda depicted the highest corruption and lowest happiness, while Sub-Saharan and some Eastern European nations showcased lower corruption but also lower happiness levels overall.
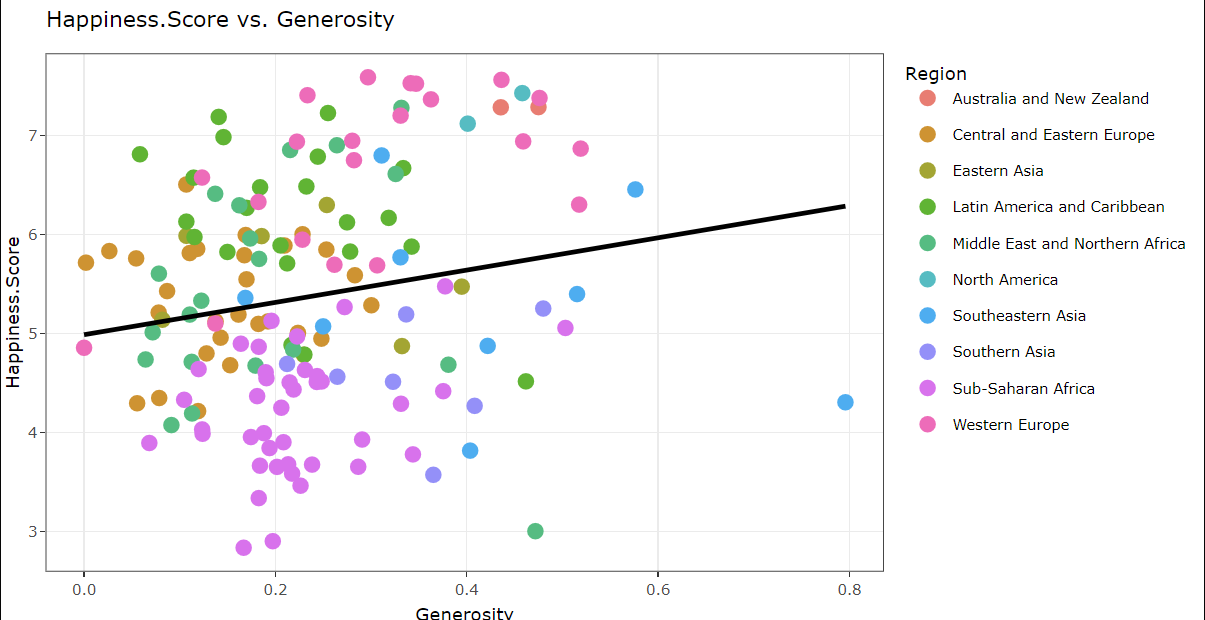
Upon analyzing the relationship between happiness scores and freedom, it’s evident that since 2019, Afghanistan consistently exhibits the lowest happiness score. Meanwhile, the Western European region consistently maintains a top-ranking position in happiness scores from 2015 to 2023. When examining the correlation between happiness scores and generosity, it becomes evident that Finland consistently secures the top position throughout the years 2015 to 2023 in terms of happiness scores.
Question 2: Patterns of change in happiness scores related to global events.
From 2015 to 2023, a series of major global events significantly impacted the happiness scores of various countries. These events, ranging from economic crises to geopolitical conflicts and health emergencies, have caused notable fluctuations in global happiness levels. In this brief introduction, we will list some of these key events and identify the countries most affected by them.
Major Events Affecting Happiness Scores (2015-2023):
covid_years_data <- bind_rows(
happiness2015 %>% mutate(Year = 2015),
happiness2016 %>% mutate(Year = 2016),
happiness2017 %>% mutate(Year = 2017),
happiness2018%>% mutate(Year = 2018),
happiness2019%>% mutate(Year = 2019),
happiness2020 %>% mutate(Year = 2020),
happiness2021 %>% mutate(Year = 2021),
happiness2022 %>% mutate(Year = 2022),
happiness2023 %>% mutate(Year = 2023)
)
filtered_covid_data <- covid_years_data %>%
filter(Country %in% c("India", "China", "United States")) %>%
arrange(Year, Country) %>%
group_by(Year) %>%
#slice_head(n = input$num_countries) %>%
ungroup()plot_ly(data = filtered_covid_data, x = ~Year, y = ~Happiness.Rank,
color = ~Region, type = 'scatter', mode = 'lines+markers',
hoverinfo = 'text',
text = ~paste("Country:", Country, "<br>Year:",
Year, "<br>Happiness Rank:",
Happiness.Rank)) %>%
layout(title = list(text = "Happiness Rank Trends"),
margin = list(t = 50),
xaxis = list(title = 'Year', tickvals = c('2015','2016',
'2017','2018',
'2019','2020',
'2021', '2022',
'2023'),
ticktext = c('2015','2016','2017',
'2018','2019','2020',
'2021', '2022', '2023')),
yaxis = list(title = 'Happiness Score'),
hovermode = 'closest')2016 Brexit Vote:
The United Kingdom experienced political and economic uncertainty, affecting its happiness scores, as well as indirect impacts on EU member states.
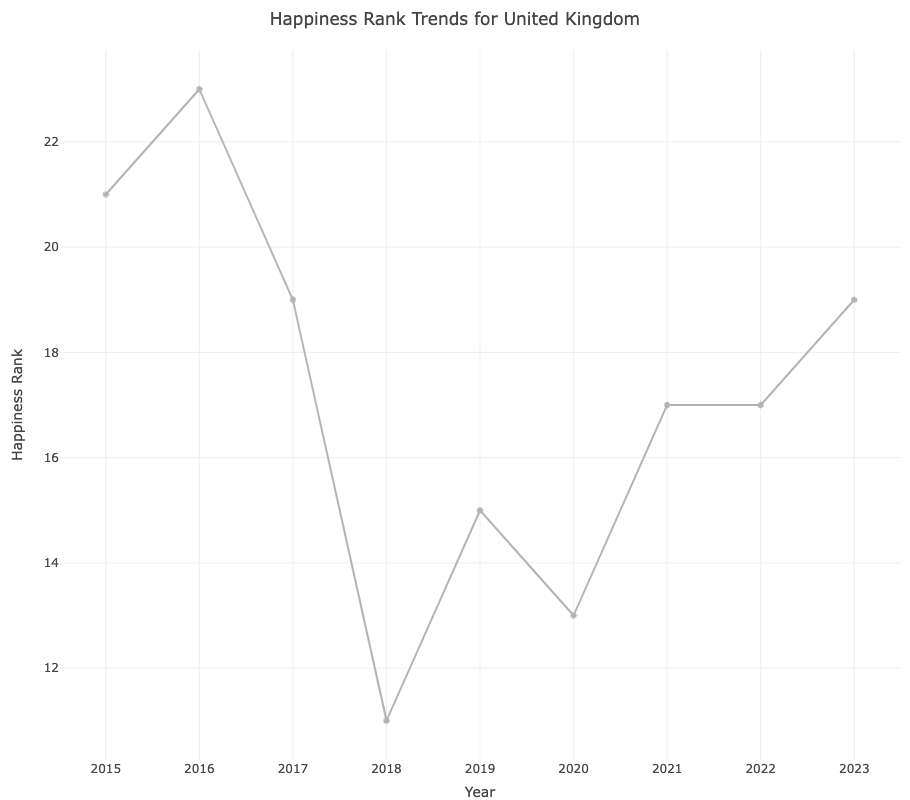
In 2016, the graph shows that the happiness rank for the United Kingdom increased, indicating a decrease in happiness. This is likely due to the uncertainty and division caused by the Brexit vote, as it introduced concerns about the UK’s economic future and its citizens’ identity within Europe. Such socio-political events typically create anxiety and can negatively impact the overall mood of the nation.
2017-2018 US-China Trade War:
Led to economic repercussions in the United States and China, as well as in countries with strong trade ties to these nations.
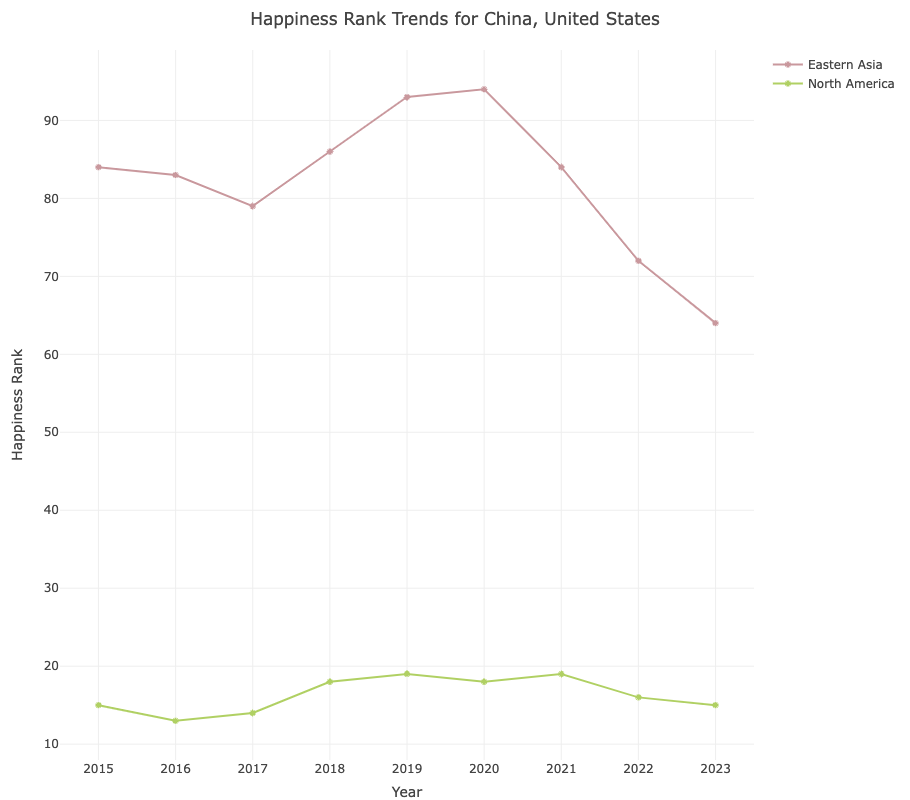
The 2017-2018 US-China trade war had a significant impact on the happiness ranks of both countries. It led to economic uncertainties, job losses, and disrupted trade, which can contribute to decreased happiness among the population. The trade war also affected global economic stability, indirectly influencing happiness ranks in other nations closely tied to the US-China trade relationship.
2019-2023 COVID-19 Pandemic:
Globally affected all countries, with significant impacts on mental health, economic stability, and overall happiness. Countries like Italy, Spain, the United States, Brazil, and India were among the hardest hit due to high infection and mortality rates.
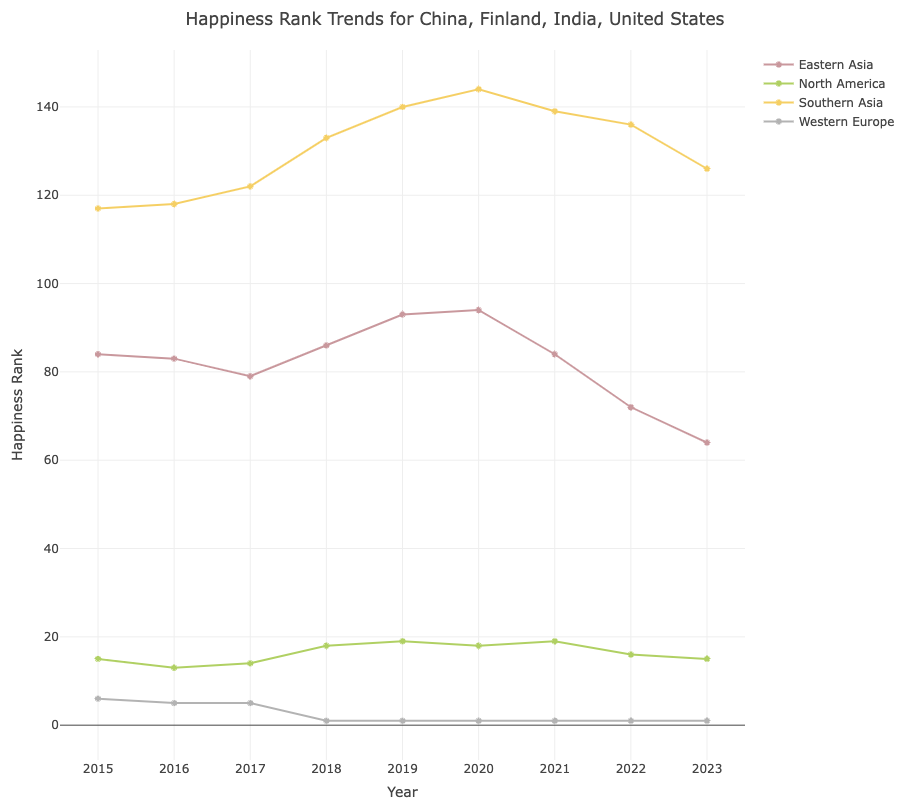
The graph indicates a general increase in happiness rank for most regions during the COVID-19 pandemic, suggesting a decline in happiness. Some regions show recovery post-pandemic, while others continue to experience lower happiness levels, with varying impacts across different parts of the world. india, china, Usa
2022 Pakistan Floods:
Heavy monsoon rains led to catastrophic flooding in Pakistan, causing massive displacement and damage to infrastructure and potentially affecting the happiness rank.
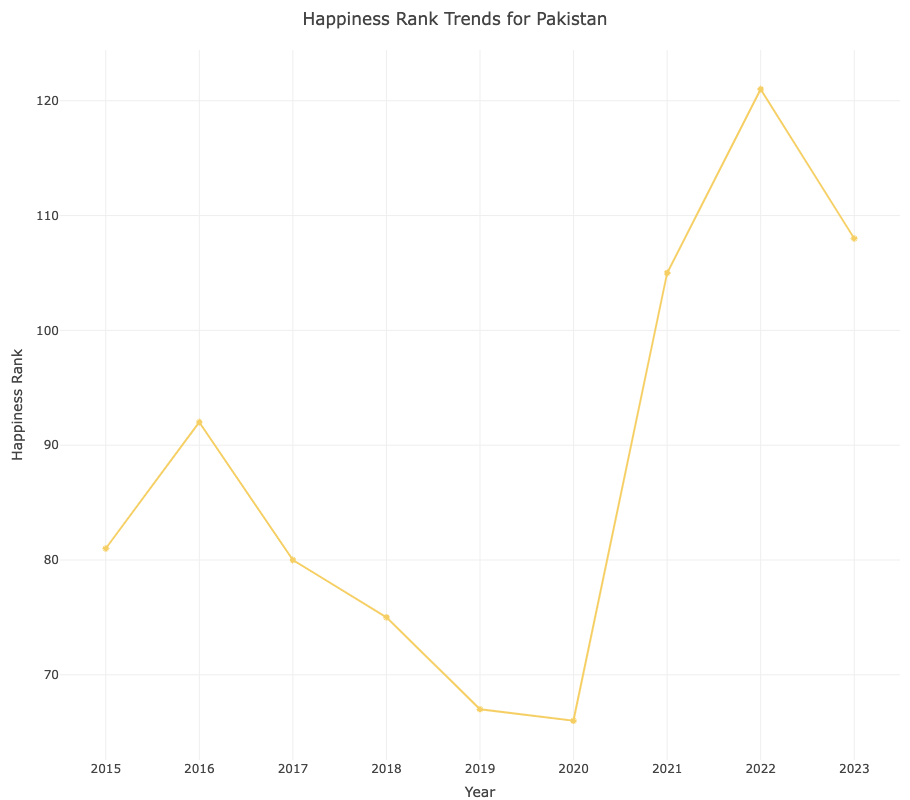
In 2022, Pakistan experienced a significant increase in its happiness rank, signifying a decrease in happiness. This was likely influenced by catastrophic flooding caused by heavy monsoon rains, resulting in displacement and infrastructure damage, which typically lowers overall happiness.
Miscellaneous Plots:
World Heatmap:
world <- world %>%
left_join(happiness2015, by = c("name" = "Country"))
ggplot(data = world) +
geom_sf(aes(fill = Happiness.Score, geometry = geometry), color = NA) +
scale_fill_viridis_c() +
theme_minimal() +
labs(fill = "Happiness Score", title = "World Happiness Map 2015")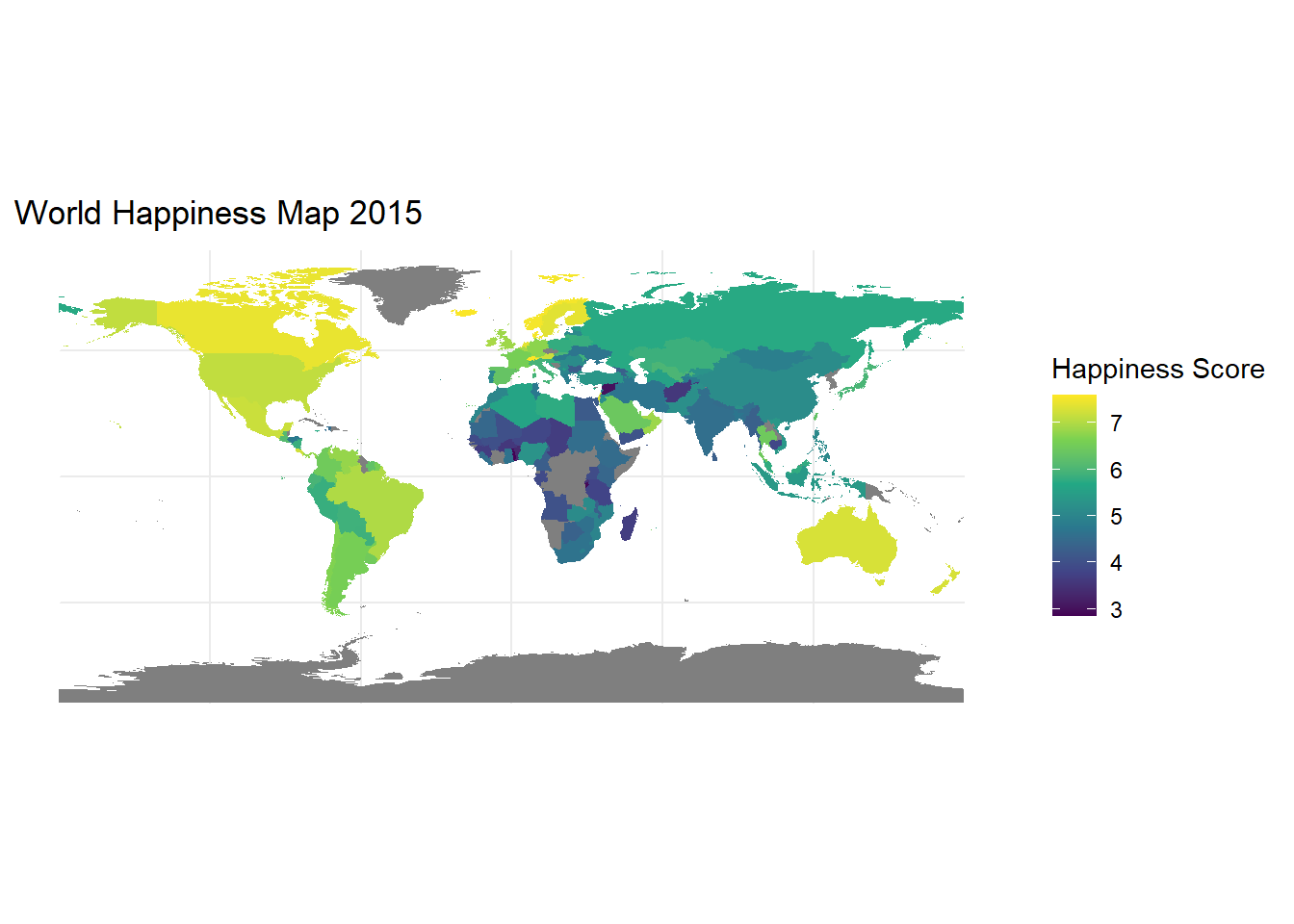
Trend Comparison:
filtered_trend <- covid_years_data |>
filter(Country %in% c("India", "China", "United States"))p <- ggplot(filtered_trend, aes(x = Year, y = Economy, color = Country)) +
geom_line() +
geom_point() +
scale_x_continuous(breaks = unique(filtered_trend$Year)) +
theme_minimal() +
#theme(legend.position = "none") +
labs(title = "Time Series Plot of Economy")
q <- ggplot(filtered_trend, aes(x = Year, y = Happiness.Score,
color = Country)) +
geom_line() +
geom_point() +
scale_x_continuous(breaks = unique(filtered_trend$Year)) +
theme_minimal() +
#theme(legend.position = "none") +
labs(title = "Time Series of Happiness Score")
(p|q) + plot_layout(guides = "collect") &
theme(legend.position = "bottom")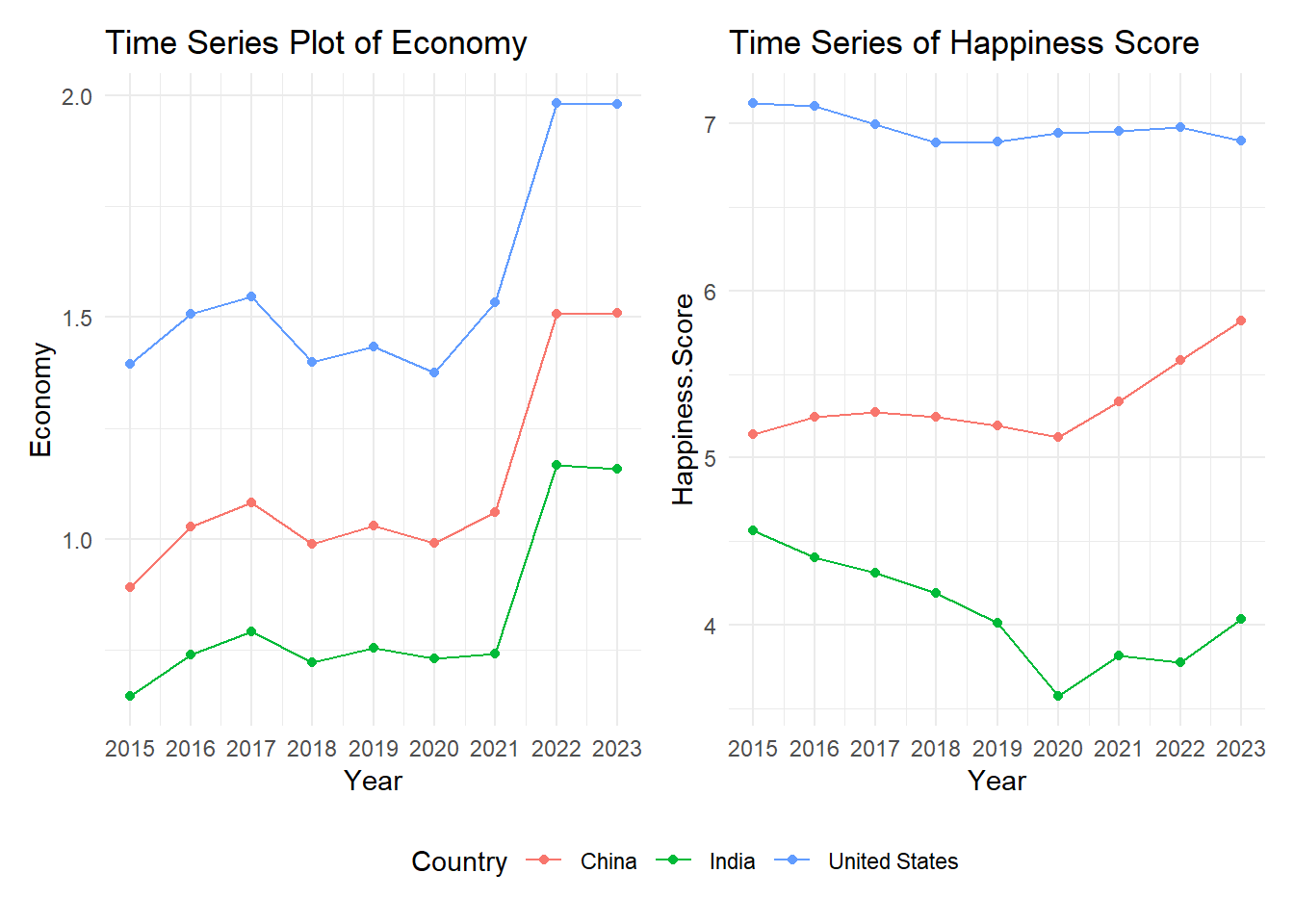
Conclusion
This World Happiness Shiny Application is not just a tool for data exploration, it is a window into the diverse and dynamic nature of global well-being. It serves as a valuable resource for researchers, policymakers, educators, and anyone interested in the study of happiness. By offering user-driven, interactive data analysis, it empowers users to uncover the complex tapestry of factors that contribute to a happier and more fulfilling global society.